mirror of
https://github.com/simon987/od-database.git
synced 2025-12-14 23:29:04 +00:00
111 lines
3.3 KiB
Markdown
111 lines
3.3 KiB
Markdown
# OD-Database
|
|
|
|
[](https://ci.simon987.net/job/od-database_qa/)
|
|
|
|
OD-Database is a web-crawling project that aims to index a very large number of file links and their basic metadata from open directories (misconfigured Apache/Nginx/FTP servers, or more often, mirrors of various public services).
|
|
|
|
Each crawler instance fetches tasks from the central server and pushes the result once completed. A single instance can crawl hundreds of websites at the same time (Both FTP and HTTP(S)) and the central server is capable of ingesting thousands of new documents per second.
|
|
|
|
The data is indexed into elasticsearch and made available via the web frontend (Currently hosted at https://od-db.the-eye.eu/). There is currently ~1.93 billion files indexed (total of about 300Gb of raw data). The raw data is made available as a CSV file [here](https://od-db.the-eye.eu/dl).
|
|
|
|
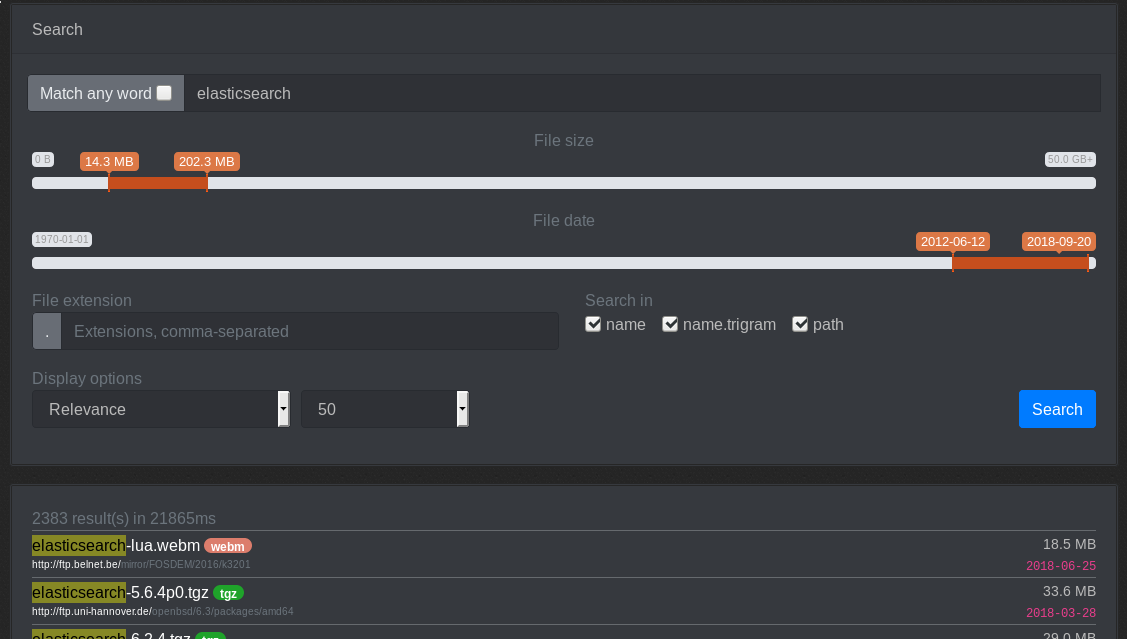
|
|
|
|
|
|
### Contributing
|
|
Suggestions/concerns/PRs are welcome
|
|
|
|
## Installation
|
|
Assuming you have Python 3 and git installed:
|
|
```bash
|
|
sudo apt install libssl-dev libcurl4-openssl-dev
|
|
git clone https://github.com/simon987/od-database
|
|
cd od-database
|
|
git submodule update --init --recursive
|
|
sudo pip3 install -r requirements.txt
|
|
```
|
|
Create `/config.py` and fill out the parameters. Sample config:
|
|
```python
|
|
# Leave default values for no CAPTCHAs
|
|
CAPTCHA_LOGIN = False
|
|
CAPTCHA_SUBMIT = False
|
|
CAPTCHA_SEARCH = False
|
|
CAPTCHA_EVERY = 10
|
|
|
|
# Flask secret key for sessions
|
|
FLASK_SECRET = ""
|
|
RESULTS_PER_PAGE = (25, 50, 100, 250, 500, 1000)
|
|
# Allow ftp websites in /submit
|
|
SUBMIT_FTP = False
|
|
# Allow http(s) websites in /submit
|
|
SUBMIT_HTTP = True
|
|
|
|
# Number of re-crawl tasks to keep in the queue
|
|
RECRAWL_POOL_SIZE = 10000
|
|
# task_tracker API url
|
|
TT_API = "http://localhost:3010"
|
|
# task_tracker crawl project id
|
|
TT_CRAWL_PROJECT = 3
|
|
# task_tracker indexing project id
|
|
TT_INDEX_PROJECT = 9
|
|
# Number of threads to use for ES indexing
|
|
INDEXER_THREADS = 4
|
|
|
|
# ws_bucket API url
|
|
WSB_API = "http://localhost:3020"
|
|
# ws_bucket secret
|
|
WSB_SECRET = "default_secret"
|
|
# ws_bucket data directory
|
|
WSB_PATH = "/mnt/data/github.com/simon987/ws_bucket/data"
|
|
# od-database PostgreSQL connection string
|
|
DB_CONN_STR = "dbname=od-database user=od-database password=xxx"
|
|
```
|
|
|
|
## Running the crawl server
|
|
The python crawler that was a part of this project is discontinued,
|
|
[the go implementation](https://github.com/terorie/od-database-crawler) is currently in use.
|
|
|
|
## Running the web server (debug)
|
|
```bash
|
|
cd od-database
|
|
python3 app.py
|
|
```
|
|
|
|
## Running the web server with Nginx (production)
|
|
* Install dependencies:
|
|
```bash
|
|
sudo apt install build-essential python-dev redis-server uwsgi-plugin-python3
|
|
```
|
|
* Configure nginx (on Debian 9: `/etc/nginx/sites-enabled/default`):
|
|
```nginx
|
|
server {
|
|
...
|
|
|
|
include uwsgi_params;
|
|
location / {
|
|
uwsgi_pass 127.0.0.1:3031;
|
|
}
|
|
|
|
...
|
|
}
|
|
```
|
|
|
|
* Configure Elasticsearch
|
|
```
|
|
PUT _template/default
|
|
{
|
|
"index_patterns": ["*"],
|
|
"order": -1,
|
|
"settings": {
|
|
"number_of_shards": "50",
|
|
"number_of_replicas": "0",
|
|
"codec" : "best_compression",
|
|
"routing_partition_size" : 5
|
|
}
|
|
}
|
|
```
|
|
* Start uwsgi:
|
|
```bash
|
|
uwsgi od-database.ini
|
|
```
|
|
|